#PostgresMarathon 2-004: Fast-path locking explained


After 2-003, @ninjouz asked on X:
If fast-path locks are stored separately, how do other backends actually check for locks?
The answer reveals why fast-path locking is so effective - and why PG 18's improvements matter so much in practice. // See lmgr/README, the part called "Fast Path Locking".
Remember from 2-002: when you SELECT from a table, Postgres locks not just the table but ALL its indexes with AccessShareLock during planning. All of these locks go into shared memory, protected by LWLocks. On multi-core systems doing many simple queries (think PK lookups), backends constantly fight over the same LWLock partition. Classic bottleneck.
Instead of always going to shared memory, each backend gets its own private array to store a limited number of "weak" locks (AccessShareLock, RowShareLock, RowExclusiveLock).
In PG 9.2-17: exactly 16 slots per backend, stored as inline arrays in PGPROC -- each backend's 'process descriptor' in shared memory that other backends can see, protected by a per-backend LWLock (fpInfoLock).
No contention, because each backend has its own lock.
We can identify fast-path locks in "pg_locks", column "fastpath".
Weak locks on unshared relations – AccessShareLock, RowShareLock, and RowExclusiveLock – don't conflict. Typical DML operations (SELECT, INSERT, UPDATE, DELETE) take these locks and happily run in parallel. While DDL operations or explicit LOCK TABLE commands create conflicts, so locks for them never go to the fast-path slots.
For synchronization, Postgres maintains an array of 1024 integer counters (FastPathStrongRelationLocks) that partition the lock space. Each counter tracks how many "strong" locks (ShareLock, ShareRowExclusiveLock, ExclusiveLock, AccessExclusiveLock) exist in that partition. When acquiring a weak lock: grab your backend's fpInfoLock, check if the counter is zero. If yes, safely use fast-path. If no, fall back to main lock table.
Therefore, other backends don't normally need to check fast-path locks - they only matter when acquiring a conflicting strong lock, which is rare (in this case: bump the counter, then scan every backend's fast-path array to transfer any matching locks to the main table).
With partitioning becoming popular, 16 slots often isn't enough. A query touching a partitioned table with multiple indexes per partition quickly exhausts the fast-path limit. When you overflow those 16 slots, you're back to the main lock table and LWLock:LockManager contention.
This became a real problem for multiple PostgresAI clients in 2023 - they were experiencing severe LWLock:LockManager contention. We had some tests where we changed FP_LOCK_SLOTS_PER_BACKEND and confirmed that it mitigates LWLock:LockManager contention in certain cases, so I proposed to make this hard-coded value configurable. Tomas Vondra was the first to respond, and it was clear he had also been studying similar cases.
In Postgres 18, the storage for fast-path locks has changed, now fast-path locks are stored in variable-sized arrays in separate shared memory (referenced via pointers from PGPROC). This allows variable sizing, so allowed number of fast-path locks for a backend scales with max_locks_per_transaction (default 64 slots). This is one of the trickiest parameters to understand fully, so we'll talk about it separately. Changing it requires Postgres restart.
To wrap a today, let's look at some benchmarks. These benchmarks were conducted by Denis Morozov from the PostgresAI team by request from GitLab – see this GitLab issue (kudos to GitLab for keeping a lot of work publicly available, for wide open source community benefits – including Postgres community!)
We'll dive into some more details in next posts; here, I provide a simplified description.
On a 128-vCPU machine, we initialize a pgbench DB without partitioning involved:
pgbench -i -s 100
and then run a series of '--select-only' pgbench runs with high number of backends ('-c/-j 100'):
pgbench --select-only -c 100 -j 100 -T 120 -P 10 -rn
pgbench's '--select-only' consists of a simple PK lookup, a SELECT to the "pgbench_accounts" table.
We do it in multiple iterations, and after each iteration, we create a new extra index on "pgbench_accounts" -- it doesn't matter which index; what matters is that we don't use '-M prepared', so we know that each call will include planning time, and therefore, all indexes will be locked with AccessShareLock. The very first iteration starts with 2 relations locked – the table itself, and its single index, the PK.
Thus, when we have 14 extra indexes, the overall number of relations is 1+1+14 = 16 and this fits into standard FP_LOCK_SLOTS_PER_BACKEND slots in PG17 or in PG18+ when max_locks_per_transaction is decreased from default 64 to 16, to match the capacity of PG17.
Let's look at the planning time and execution time separately:
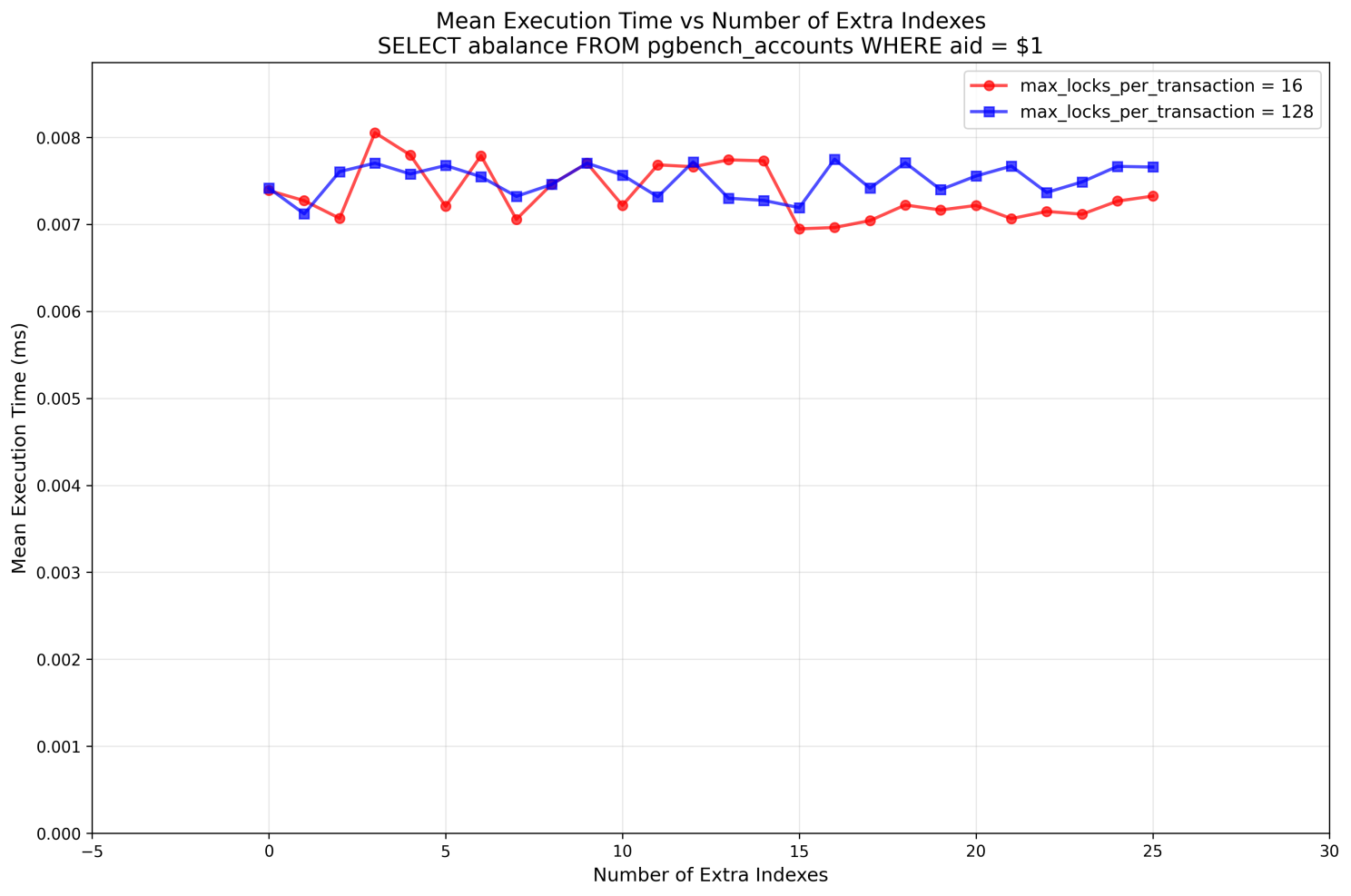
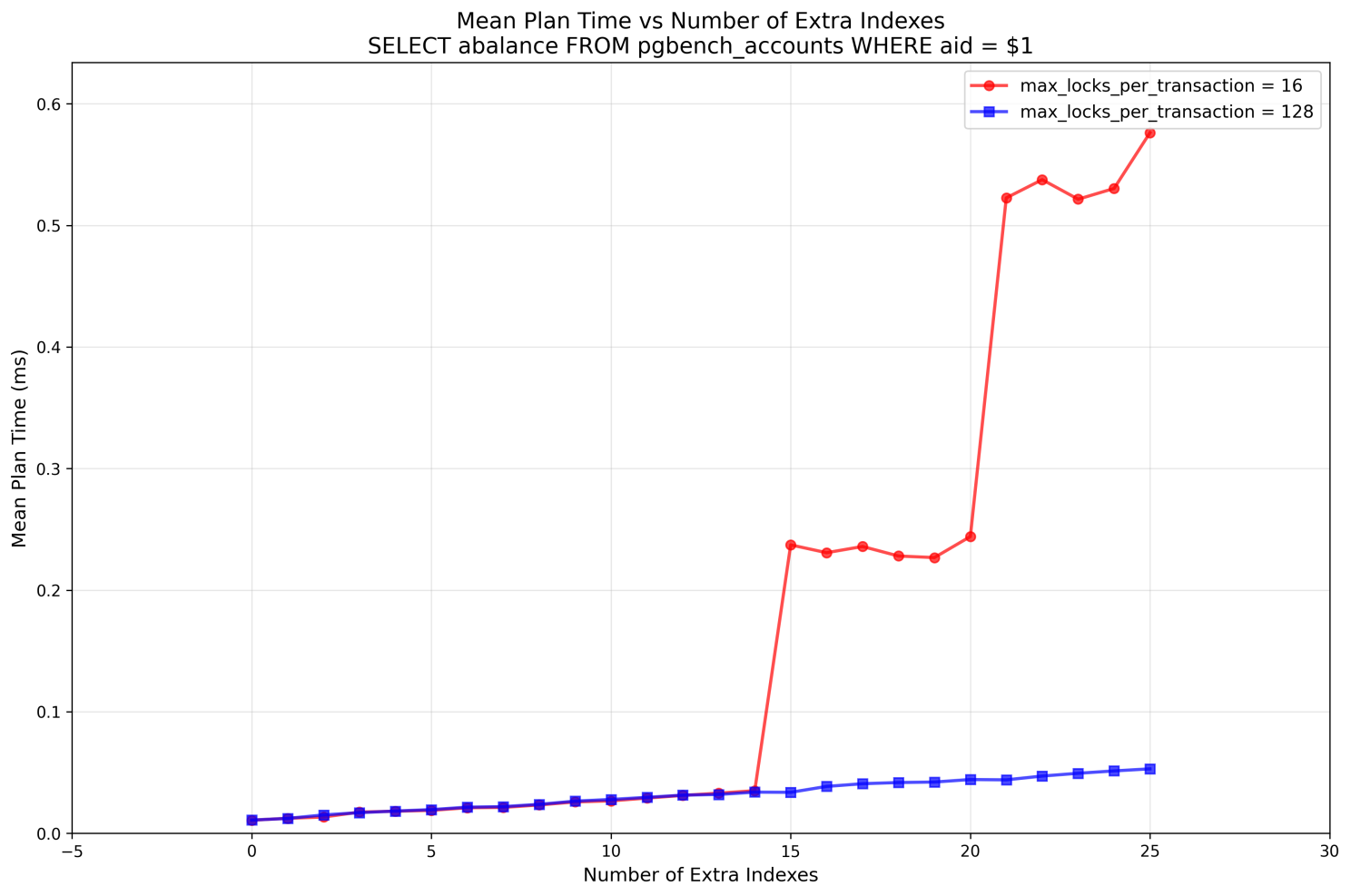
What can we see here:
- execution time is stable, doesn't depend on the number of indexes
- as for the planning time, indeed, up to 14 extra indexes we see only slow growth of latency (locking of each index costs us a little bit of time -- so we can say, that extra indexes always slightly slow down SELECTs, unless prepared statements are used; an interesting fact on its own)
- and when we have 15 extra indexes, for
max_locks_per_transaction=16in PG18 (or in PG17 regardless of this setting), this becomes a game-changer – we see an obvious sign of a performance cliff, the planning part of the latency jumps - while if we keep
max_locks_per_transactionat the default 64, or – like in this case, raise to 128, we can keep adding indexes without the planning time being significantly affected
Let's look at wait events:
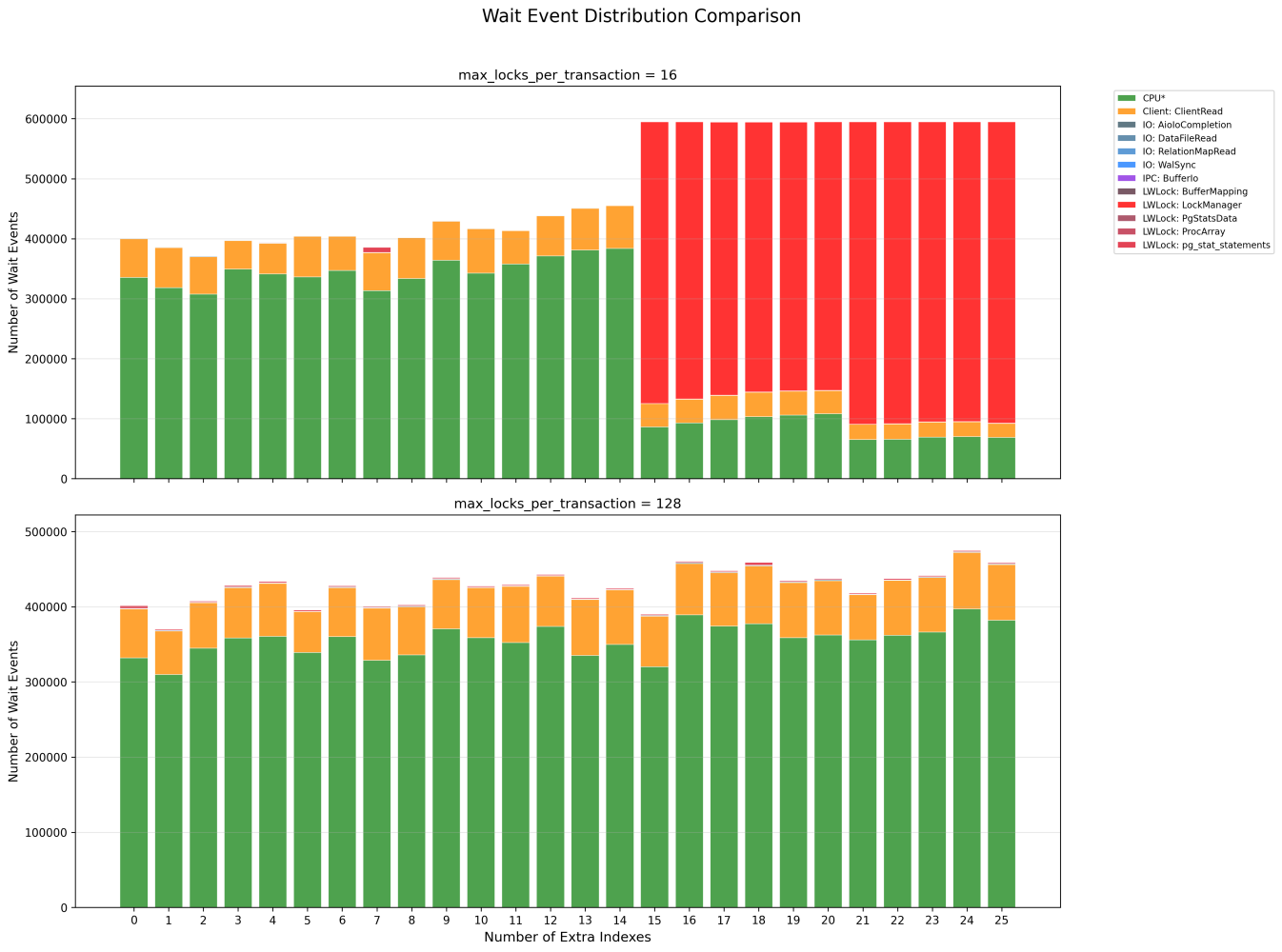
Here it is, LWLock:LockManager.
Notice how PG 18 with max_locks_per_transaction=16 (top; and PG17 would look similar) shows massive red bars of LWLock:LockManager waits at higher index counts, while PG 18 with max_locks_per_transaction=128 (bottom) stays mostly green (active execution).
But are there downsides?
This is where I'm genuinely curious. The implementation seems almost too good to be true. Let me think through potential tradeoffs:
Memory overhead: with max_locks_per_transaction=64, you get 64 slots per backend. Each slot needs ~4 bytes for the OID plus some bits in fpLockBits. Some hundreds of bytes per backend. Looks negligible.
Strong lock acquisition: here's where it gets interesting. When we take a strong lock (AccessExclusiveLock for DDL like ALTER TABLE or DROP), Postgres needs to scan every backend's fast-path array to transfer matching locks to the main hash table. With, say, 128 slots instead of 16, does this become noticeably slower? In fact, looking at the code (FastPathTransferRelationLocks) - it only scans the relevant group for that relation (still just 16 slots), not the entire array! So even with 1024 groups = 16,384 total slots, it only touches 16 slots per backend. Clever!
The grouping hash: relations are distributed across groups via (relid * 49157) % groups (code here). What if the workload has unfortunate OID patterns that cause clustering? Nope -- the prime number multiplication spreads even consecutive OIDs across groups effectively.
Am I missing something? Would love to hear your thoughts, especially if you've tested this in PG 18 or have ideas for additional benchmarks.
Summary
Fast-path locking lets backends avoid fighting over shared lock tables for common operations like SELECT. PG 17 and earlier: 16 slots per backend. PG 18: scales with max_locks_per_transaction (default 64).
If you have partitioned tables with indexes and see LWLock:LockManager waits, upgrading to PG 18 will likely help you fully solve this kind of contention!
Huge thanks to Tomas Vondra for implementing the optimization that landed in Postgres 18! He has an excellent presentation about this work - highly recommend watching it.