How NOT EXISTS beat EXISTS by 26x — index size and heap fetches


Two queries. Same result. One is 26x faster — and it reads 53x fewer disk pages.
The difference is one word: NOT.
The setup
A classic soft-delete pattern: a posts table with a boolean deleted flag.
Most posts are active — 2% are soft-deleted.
create table posts (
post_id bigint primary key,
deleted boolean not null default false,
pad text not null -- wide rows, ~200 bytes each
);
-- two partial indexes:
create unique index posts_not_deleted_id_key
on posts (post_id) where not deleted; -- 98%: ~49M rows
create unique index posts_deleted_id_key
on posts (post_id) where deleted; -- 2%: ~1M rows
Table: 50 million rows, 15 GiB on disk. Indexes:
| Index | Covers | Size |
|---|---|---|
posts_not_deleted_id_key | 49M active rows | 1,050 MiB |
posts_deleted_id_key | 1M deleted rows | 22 MiB |
The query: find all post_tag rows for a given tag list where the post is not deleted.
Two ways to write it
Query 1 — filter for active posts directly:
select pt.*
from post_tag pt
where pt.tag_id = any($1)
and exists (
select from posts
where posts.post_id = pt.post_id
and not deleted
);
Query 2 — exclude deleted posts:
select pt.*
from post_tag pt
where pt.tag_id = any($1)
and not exists (
select from posts
where posts.post_id = pt.post_id
and deleted
);
Same result. Different index. Dramatically different performance.
Benchmark results
Environment: Postgres 18.3, 8 dedicated cores, 32 GiB RAM,
cold OS page cache before each run (drop_caches + PG restart),
dirty visibility map (10% of rows updated — normal for any active production table),
work_mem = 4MB (default), shared_buffers = 128MB (default).
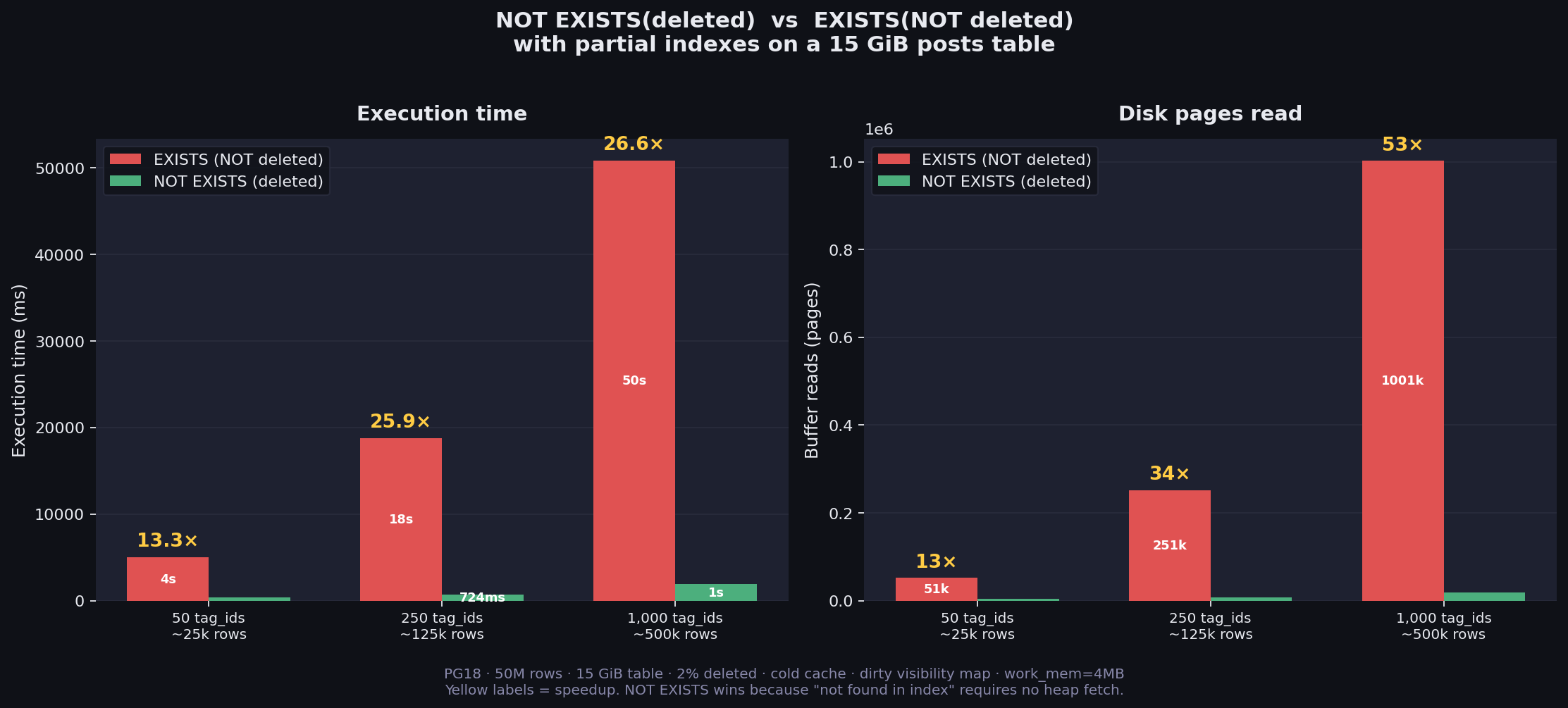
| tag_ids | Q1: EXISTS(NOT deleted) | Q2: NOT EXISTS(deleted) | Speedup |
|---|---|---|---|
| 50 (~25k rows) | 4,984 ms | 376 ms | 13x |
| 250 (~125k rows) | 18,777 ms | 724 ms | 26x |
| 1,000 (~500k rows) | 50,791 ms | 1,907 ms | 27x |
Buffer reads:
| tag_ids | Q1 reads | Q2 reads | Ratio |
|---|---|---|---|
| 50 | 51,952 | 4,147 | 13x |
| 250 | 251,964 | 7,435 | 34x |
| 1,000 | 1,001,934 | 18,765 | 53x |
Q2 reads 13–53x fewer pages from disk. Both queries use Nested Loop —
work_mem=4MB prevents the hash table from fitting in memory for either query.
Why
Two factors stack on top of each other, both pointing the same direction.
Factor 1: index size
posts_deleted_id_key is 22 MiB — it fits entirely in shared_buffers after
the first access. Every subsequent lookup is a memory hit.
posts_not_deleted_id_key is 1,050 MiB — it does not fit. Each of the thousands
of point lookups in a nested loop hits a different index page. On a 15 GiB table
that is not in memory, that means random I/O on every single lookup.
Factor 2: "not found in index" requires no heap fetch
This is the key insight.
When Q2 looks up a post in posts_deleted_id_key (the deleted index) and
finds nothing — it's done. No row in the index means no row in the table.
No heap fetch. No visibility check. The visibility map doesn't matter at all.
When Q1 looks up a post in posts_not_deleted_id_key (the active index) and
finds a row — Postgres must verify the row is visible to the current
transaction. If the page is not all-visible in the visibility map — normal for
any actively updated table — a heap fetch is required. That is a random read
into a 15 GiB table that doesn't fit in RAM.
Heap fetches measured:
| Q1: EXISTS(NOT deleted) | Q2: NOT EXISTS(deleted) | |
|---|---|---|
| 50 tag_ids | 26,938 heap fetches | 576 |
| 250 tag_ids | 132,246 heap fetches | 2,830 |
| 1,000 tag_ids | 526,367 heap fetches | 10,801 |
Q1 heap-fetches nearly every active post — 27k to 526k random reads into a wide table that doesn't fit in memory.
Q2 heap-fetches only the deleted posts (those it actually found in the small index). For 98% of lookups, it simply doesn't find anything — and stops there.
The takeaway
"Not found in the index" is free. "Found" requires a heap fetch.
When 98% of your lookups are for the majority case (active posts), you want those lookups to return "not found" against the small index — not "found" against the large one.
Use
NOT EXISTSwith a partial index on the minority (deleted, disabled, flagged) — notEXISTSwith a partial index on the majority.
This pattern was first identified by Maxim Boguk on a 400 GiB production table — where the speedup was approximately 50x.
Reproduce it
-- setup (~3-5 min for 50M rows on modern hardware)
create table posts (
post_id bigint primary key,
deleted boolean not null default false,
pad text not null default repeat('x', 200)
);
insert into posts (post_id, deleted)
select g, (random() < 0.02) from generate_series(1, 50000000) g;
create unique index posts_not_deleted_id_key on posts (post_id) where not deleted;
create unique index posts_deleted_id_key on posts (post_id) where deleted;
-- dirty the VM (simulate an active table)
update posts set pad = repeat('y', 200) where post_id % 10 = 0;
analyze posts;
-- run both queries with EXPLAIN (ANALYZE, BUFFERS)
-- look at: Execution Time, Heap Fetches, Buffers: shared read