#PostgresMarathon 2-005: More LWLock:LockManager benchmarks for Postgres 18

In 2023-2024, after incidents that multiple customers of PostgresAI experienced, when production nodes were down because of LWLock:LockManager contention, we studied it in synthetic environments.
At that time, we managed to reproduce the issue only on large machines – ~100 or more vCPUs.
With PG18 release, this question started to bother me again: can we experience LWLock:LockManager on smaller machines?
Denis Morozov just published results of benchmarks that successfully reproduce LWLock:LockManager contention in PG18 on 16-vCPU VMs.
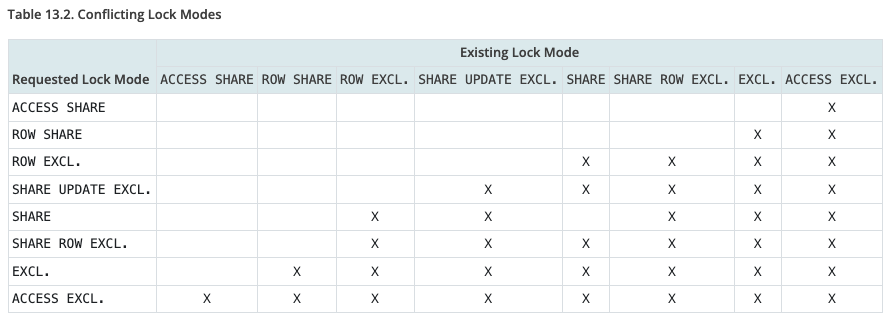
As before, we took standard pgbench, with -s100 (no partitioning), and started running the standard "--select-only" workload that SELECTs random rows in "pgbench_accounts". Originally, the table has only 1 index – so at planning time, Postgres locks 2 relations with AccessShareLock; then we add one more index at each step.